20. 10. 2008
Podle čeho řadí vyhledávání na Centrum.cz
Přidáním parametru &debug=1 do adresy libovolného vyhledávání na Centrum.cz se dostanete do rozšířeného výpisu výsledků vyhledávání. Z něj jsou patrné zákonitosti řazení, druhy výsledků vyhledávání, penalizace a váhy hledání. Na tenhle debugovací výpis chodím už mnoho let. Nechtěl jsem to publikovat, aby tuhle možnost Centrum nevypnulo -- při průzkumu výsledků se člověk hodně poučil i pobavil. Protože ale za pár dnů přejde Centrum na vyhledávání v Google (Atlas už přešel), tahle sranda stejně končí, takže je čas si Morfeo na Centru trochu rozebrat. Předem se, moji milí čtenáři, omlouvám na obě strany. Jednak budu hodně zestručňovat a za druhé to bude dnes dlouhé povídání.
První věc, kterou budete potřebovat, je hledat něco na centrum.cz a přidat si do adresy parametr &debug=1. Nebo si můžte kliknout na odkaz na rozšířený výpis hledání třeba slova Rhodos na Centrum.cz. Měla by se uložit cookie a debugovací hlášky budete mít pak už u všech hledání. Dá se to vypnout zadáním &debug=0
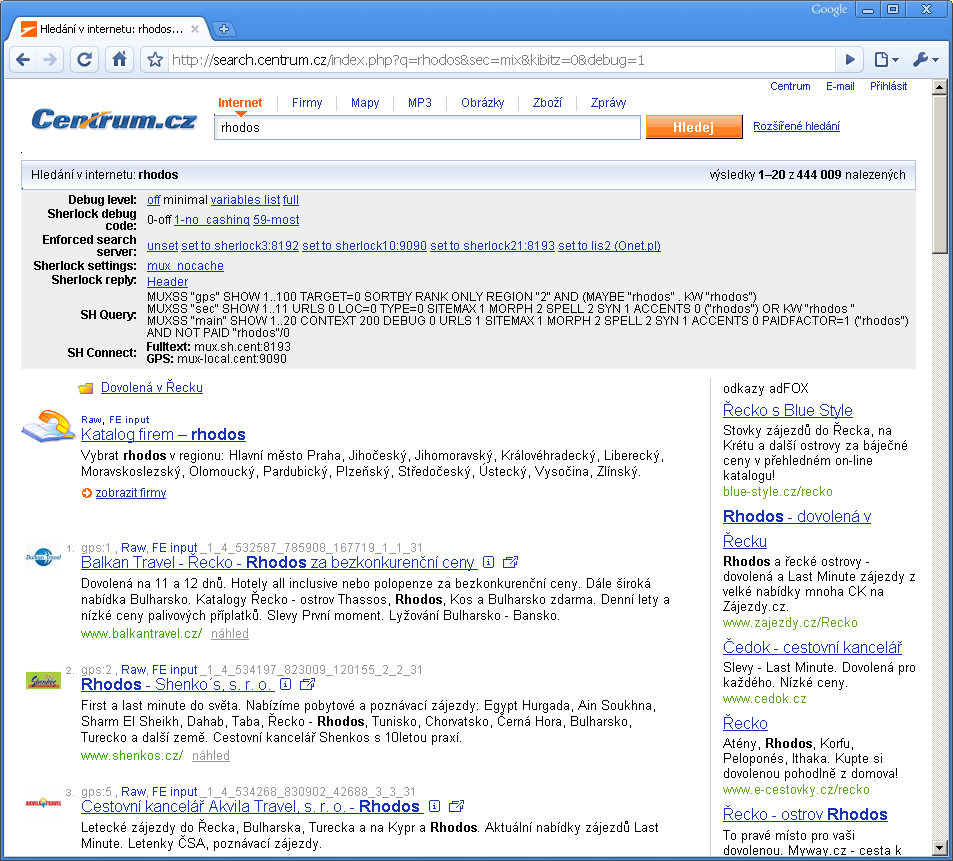
Typy výsledků
Každý výsledek v debugovacím výpisu začíná kódem, který označuje typ výsledku.
- raw je napevno vložená upoutávka na služby Centra (něco jako hinty v Seznamu)
- gps není navigace, ale Garance První Strany. To jsou placené výsledky.
- sec je nalezená sekce v katalogu Centra
- ftxt je fulltext Morfea, to je to nejzajímavější
Většinou jsou výsledky řazeny v tom pořadí, jak jsem je teď uvedl. Ale někdy jsou malinko přeházené. Také pokud nejsou žádné placené gps výsledky, dá se nahoru reklama AdFox (nemá číslování ani kód). Výsledky se dají rozlišit i v normálním zobrazení, protože garance první strany obvykle má logo. Ale neplatí to vždy a i některé fulltextové výsledky registrované v katalogu mohou mít logo.
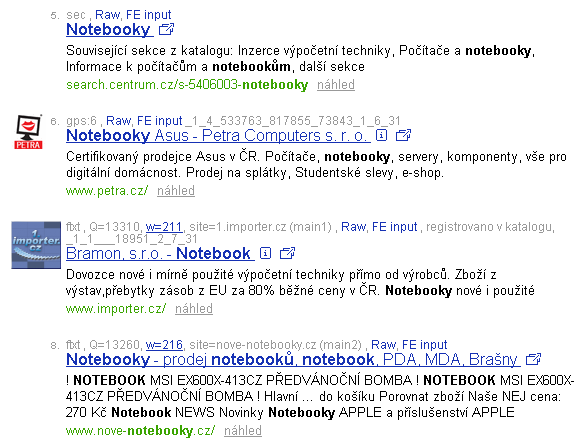
Nejzajímavější věc je koukat se na váhy řazení. Nad každým fulltextovým výsledkem je malý odkaz w=číslo, třeba w=227. Odkaz vede na detailní výpočet relevance. Ještě před odkazem je uvedeno číslo Q, například Q=13370. Toto číslo Q je výsledná veličina, podle kterého se fulltextové výsledky řadí. Hodnoty jsou vidět i bez debug módu ve výsledcích na morfeo.centrum.cz, tam ale není ten odkaz w=číslo. Blbě se mi to popisuje, prostě si to zkuste proklikat (máte na to ještě pár dnů).
Jak řadí fulltext - jednoslovný dotaz
Jednoslovný dotaz ukážu na příkladu výpisu. Takováhle věc vyleze, když se nad výsledkem klikne na to W=číslo:
Word <rhodos>: Q=11100
Base: 10000
1st match: title[0] (100) => 1000
2nd match: hdr2 (80) => 100
Custom matcher: Q=0
Static weight 210 x 1 (Q=2100) => total Q=13200
Výklad: hledané slovo se hledá na různých místech stránky, v jejím katalogovém záznamu a v textu zpětných odkazů. Podle toho, kde se slovo najde, stránka dotane různý počet bodů (podle níže uvedené tabulky). Nejlepšímu výskytu (1st match) se body vynásobí deseti, druhému nejlepšímu výskytu (2nd match) se body vynásobí číslem 1,25. Ostatní výskyty slova na stránce se bez milosti zahodí.
| kód výskytu | body Q | význam |
|---|---|---|
| ctitle | 110 | slovo je v katalogovém titulku |
| cdesc | 30 | v katalogovém popisku |
| title | 100 | v titulku stránky (tag <title>) |
| hdr2 | 80 | nadpisy h1, h2 a h3 |
| hdr1 | 50 (-10) | nadpisy h4, h5 a h6 |
| text | 20 (-70) | normální text |
| emph | 50 (-40) | zvýrazněné slovo, vnitřek tagů em, strong, i a b |
| small | 10 | vnitřek tagu small |
| alt | 10 | alty obrázků |
| ext | 80 | slovo je v textu odkazů mířících na stránku |
| meta | 0 | slovo se vyskytuje v meta description (možná i keywords, nevím) |
| host | 0 | asi výskyt v doméně, nevím |
| urlword[3] | 90 | slovo je v doméně druhého řádu |
| urlword[1] | 25 | slovo je v subdoméně |
Čísla v závorkách se týkají situace, kdy je slovo v jiném tvaru, než uživatel hledá. Každé slovo také automaticky dostává deset tisíc bodů jako základ - Base. To je evidentně pozůstatek z doby, kdy se hledalo také s operátorem OR. Díky základu ale případná záporná čísla neznamenají žádnou penalizaci.
Custom matcher nevím, co znamená. Co jsem si všimnul, je vždycky nula.
Nakonec se vezme Static weight, tedy ono číslo W. W je podle mého názoru buďto přímo PageRank, nebo něco, co se mu velmi podobá. Evidentně je to osmibitové skalární číslo, které má vypočítané každá stránka. Static weight se ve výpočtu vynásobí deseti (a počtem hledaných slov, u jednoslovného dotazu to tedy není znát) a přičte se k výsledku. Vyjde nějaké Q, podle kterého se výsledky seřadí. To je pro jednoslovný dotaz vše.
Víceslovný dotaz
Hodně se to podobá jednoslovnému dotazu, protože Morfeo zpracovává víceslovný dotaz po jednotlivých slovech (přesněji řečeno po částech, tomu říkám per partes). Příklad: hledáme [pekelně dobré ráno] a jeden z výsledků má tuto kartu:
Word <pekelně>: Q=10200
Base: 10000
1st match: text (20) => 200
Word <dobré>: Q=10862
Base: 10000
1st match: hdr2 (80) => 800
2nd match: emph (50) => 62
Word <ráno>: Q=10500
Base: 10000
1st match: emph (50) => 500
Custom matcher: Q=0
Near #0: Q=4100
Static weight 172 x 3 (Q=5160) => total Q=40822
- Slovo pekelně se našlo jenom v textu, a tak se připočítá Base a deset krát dvacet.
- Slovo dobré se našlo v nadpisu (80 krát 10) druhý nejlepší výskyt byl ve zvýrazněném textu (50 krát 1,25). Další výskyty se zahazují. Plus Base.
- Slovo ráno se opět našlo jenom jednou, bylo to ve zvýrazněném textu, což je 50 krát 10. Plus samozřejmě base.
- Nová položka je tady Near #0. Přiznám se, že to je pro mě jediná záhada ve výpočtu. V případě dvou slov vedle sebe dosahuje vždy hodnoty 4100.
- Nakonec se připočte statická váha, vynásobí se třemi (tři slova dotazu) a deseti.
- Vyjde nějaký součet a podle toho se řadí.
Někdy se stane, že se hledaný dotaz ve spojené formě shoduje s částí adresy nějaké stránky. Například pokud hledám dotaz [jak podnikat], dostanu na kartě výsledku ještě jednu složku, totiž spojené slovo:
Word <jakpodnikat>: Q=21900
Base: 21000
1st match: urlword[3] (90) => 900
Takové složené slovo se musí s dotazem shodovat přesně, nestačí jenom jedna jeho část. A hledá se pouze v URL adrese.
Toť opět vše. Jak vidíte, není to zas tak komplikované. Pominu-li složku Near, všechno tohle hledání a řazení se dá udělat s velmi jednoduchým idexem, který ani nezaznamenává pozice slov. Samozřejmě že Morfeo poziční index má (to je vidět z toho, jaké umí pokročilé operátory), ale je evidentní, že ho moc nepoužívá. Už protože z té veličiny Near občas lezou hodně zvláštní čísla (zaznamenal jsem hodnoty 9350, 12300, 4100, 5250 a 4920).
Zajímavá věc je zpracování dotazu s předložkou. Když hledáte [chleba se sádlem], rozloží si ho vyhledávač na slova "chleba" "sádlem" a "se sádlem".
Penalizace
Našel jsem čtyři druhy penalizací. Ruční penalizace pro jednu konkrétní stránku, snížení ranku pro celou doménu, úplné vyřazení domény a automatická penalizace, když stránce třeba chybí titulek. Pouhé snížení ranku (tedy onoho w -- static weight) znamená skutečně citelnou penalizaci, protože ostatní složky jsou hodně diskrétní (když se to vygrafuje, vznikají stolové hory), takže tam každý spojitější příznak (tedy rank) nadělá velké rozdíly, zejména u konkurenčních dotazů. Typy penalizace:
- Ruční penalizace pro jednu stránku je vidět v případě hlavní stránky idnes.cz. Má snížený rank o 150 bodů s poznámkou giant class. Vida. Stejnou penalizaci má hlavní stránka mapy.cz. Hmmmm.
- Ruční penalizace celého webu se týká všech stránek na doméně Seznam.cz (o 90 bodů, hlavní stránka o 40), toplist.cz (o 50 bodů), blog.cz (o 20 bodů) a estranky.cz (o celých 150 bodů). Morfeo téhle penalizaci zřejmě říká filters. Perličkou je penalizace všech stránek domény katalog.atlas.cz o 50 bodů. Asi si Centrum ještě nevšimlo, že jsou s Atlasem spojeni.
- Evidentně ruční úplné vyřazení celé domény z indexu. Zkuste si schválně najít něco z domény www.firmy.cz nebo www.zbozi.cz. Nepovedlo, že?
- Automatická penalizace jednotlivých stránek na základě pravidel. Našel jsem penalizaci ranku za chybějící titulek. Morfeo umí také krásnou věc, když je na stránce příliš mnoho zvýrazněného textu, tak sníží význam zvýrazněného textu a nadpisů na úroveň textu normálního.
Nic proti penalizaci konkurence. Centrum se při vyvíjení vyhledávače hodně nadřelo, takže si se svou databází určitě mohou dělat, co chtějí. Na druhou stranu těžko říct, jestli to pomůže hledajícím uživatelům, když třeba nemůžou najít Idnes. Inu... chtěl jsem na téma vyhledávání v Centru napsat ještě filosofický traktát a zmínit další zvláštnosti (hlavně o duplicitách), ale asi to odložím. Už tak to bylo dneska hodně dlouhé. Každopádně cítím k Morfeu hlubokou úctu a bude se mi stýskat.
Ještě pár odkazů
Pro zbrklé čtenáře ještě jednou odkaz na zobrazení debugovacího módu vyhledávání Centra.
5 kroků k zachování bezpečnosti (hlavně bod 2 -- rýpnutí pro zasvěcené).
4 roky starý rozhovor o Morfeu se zajímavými informacemi mezi řádky.
Zkracovač adres, kdybyste snad měli nutkavou potřebu v komentářích odkazovat na zajímavé výsledky debug módu.
Další články jsou v archivu.
Nejnovější příspěvky na hlavní stránce blogu.